인공지능/Machine Learning
[ML] K-means clustering 예제
유일리
2022. 10. 18. 20:58
dataset
import pandas as pd
data = pd.read_excel('/content/CustomerDataSet.xlsx')
data
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
%matplotlib inline
data = pd.read_excel('/content/CustomerDataSet.xlsx')
data
processed_data = data.copy()
#데이터 전처리 - 정규화를 위한 작업
scaler = MinMaxScaler()
scaler.fit(processed_data[['ItemsBought','ItemsReturned']])
processed_data[['ItemsBought','ItemsReturned']] = scaler.transform(processed_data[['ItemsBought','ItemsReturned']])
#화면 figure 생성
plt.figure(figsize=(10,6))
for i in range(1,7):
model = KMeans(n_clusters=i)
model.fit(processed_data[['ItemsBought','ItemsReturned']])
model_predict = model.predict(processed_data[['ItemsBought','ItemsReturned']])
centroids = model.cluster_centers_
print(model.cluster_centers_)
plt.figure(figsize=(16,8))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
#클러스터링 그리기
plt.scatter(processed_data['ItemsBought'],processed_data['ItemsReturned'],c=model_predict)
plt.scatter(centroids[:,0],centroids[:,1],c='black',s=150,alpha=0.8)
plt.show()

#플로팅하기
plt.scatter(data['ItemsBought'],data['ItemsReturned'],c=model_predict)
#우편번호로 범례달기
for(index, c_id, bought, returned, zip_code, product) in data.itertuples():
plt.annotate(zip_code,(bought+0.6,returned+0.6))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
plt.show()
%matplotlib inline
model=KMeans(n_clusters=3)
model.fit(processed_data[['ItemsBought','ItemsReturned']])
model_predict = model.predict(processed_data[['ItemsBought','ItemsReturned']])
centroids = model.cluster_centers_
print(model.cluster_centers_)
plt.figure(figsize=(16,8))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
#클러스터링 그리기
plt.scatter(processed_data['ItemsBought'],processed_data['ItemsReturned'],c=model_predict)
plt.scatter(centroids[:,0],centroids[:,1],c='black',s=150,alpha=0.8)
plt.show()
#클러스터 0로 분류된 데이터를 추출해보자
data[model_predict==0]
#클러스터 1로 분류된 데이터 추출
data[model_predict==1]
#클러스터 2로 분류된 데이터 추출
data[model_predict==2]
#create a scatter plot
plt.scatter(processed_data['ItemsBought'],processed_data['ItemsReturned'],c=model_predict)
#각 클러스터와 Product ID의 관계를 시각화
for index,c_id,bought,returned,zip_code,product in processed_data.itertuples():
plt.annotate("Cluster{}:{}".format(model_predict[index],product),(bought,returned))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
plt.show()
#create a scatter plot
plt.scatter(data['ItemsBought'],data['ItemsReturned'],c=model_predict)
#각 클러스터와 지역과의 관계 시각화
for (index,c_id,bought,returned,zip_code,product) in data.itertuples():
plt.annotate(zip_code,(bought+0.6,returned+0.6))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
plt.show()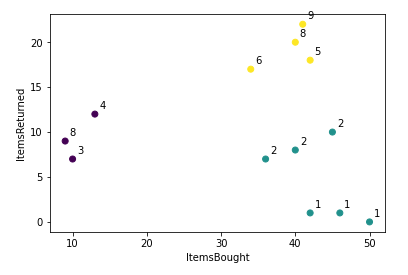
https://github.com/erica00j/machinelearning/blob/main/Kmeans_Customer1.ipynb