이전에 진행했던 Beautifulsoup로 웹 크롤링하기를 하던 중 문제가 생겼다.
바로 상품 이미지를 가져오는 부분에서 None이 찍히는것..! 이미지 주소를 타고 들어가보니 이런 에러가..

Beautifulsoup를 사용하게 되면 웹서버에서 처음 제공하는 원본 html을 가지고 오기 때문에 이후에 js가 추가적인 내용을 동적으로 생성하거나 변경하면 bs로만으로 가지고 올수가 없다.
따라서, 웹 페이지를 실제 로드하고 js를 실행할 수 있는 웹 드라이버 selenium을 사용해서 최종 html을 가지고 와야한다.
즉, 동적웹을 크롤링하려면 selenium을 써줘야 하는것!!
오늘은 이 Selenium을 사용해 상품 리뷰를 가지고 와 볼것이다.
이 상품에 대한 리뷰 정보를 가져와보자.
https://www.musinsa.com/app/goods/836499
비바스튜디오(VIVASTUDIO) LOCATION CREWNECK [INDIGO BLUE] - 사이즈 & 후기 | 무신사
제품분류 : 상의 > 맨투맨/스웨트셔츠 브랜드 : 비바스튜디오(VIVASTUDIO) 제품번호 : KSVT20 제품 : LOCATION CREWNECK [INDIGO BLUE] - 46,400 원산지 : 대한민국
www.musinsa.com
우선 시작하기 전에 필요한 라이브러리를 설치해준다.
pip install selenium
pip install webdriver-manager
필요한 라이브러리를 import해준다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import time
리뷰 내용 중 원하는 정보만 가지고 오는 함수를 작성한다.
def reviewObject(reviewElements):
reviews = []
for re in reviewElements:
review = {}
try:
profile_element = re.find_element(By.CSS_SELECTOR, 'p.review-profile__body_information')
review["profile"] = profile_element.text
except:
review["profile"] = "비회원"
try:
size_element = re.find_element(By.CSS_SELECTOR, 'span.review-goods-information__option')
review["size"] = size_element.text
except:
review["size"] = "None"
try:
score = re.find_element(By.CSS_SELECTOR, 'span.review-list__rating__active')
score_percent = score.get_attribute('style').split('width:')[1].split('%')[0].strip()
review["score"] = int(score_percent) // 20
except:
review["score"] = "None"
try:
content_element = re.find_element(By.CSS_SELECTOR, 'div.review-contents__text')
review["content"] = content_element.text.replace('\n', '')
# review_content = content_element.text.replace('\n', '')
# reviews.append(review_content)
except:
review["content"] = "None"
# reviews.append("")
reviews.append(review)
return reviews
리뷰 작성자의 프로필 정보(여성, 163cm, 51kg 등)를 가지고 오고, 존재하지 않는다면 비회원으로 저장한다. 또한, 리뷰 작성자가 구매한 옷의 사이즈 정보, 별점 점수, 리뷰 내용을 가지고 온다.
이제 selenium 사용을 위한 설정을 해보자.
우선 selenium을 사용하기 위해서는 설치되어 있는 chrome 버전에 맞게 webdriver를 설치해야 한다.
사실 webdriver_manager 패키지를 사용하면 코드를 통해 자동으로 호환되는 ChromeDriver를 다운로드해주지만..내 chrome 버전은 가장 최신인 119.0.6045.124 라서 이에 맞는 드라이버 설치를 못하는 것 같다. (현재 지원하는 드라이버는 114버전까지 나온듯...)
브라우저 버전은 주소창에 ' chrome://version/'을 입력해서 확인할 수 있다. 114버전 이전꺼라면 https://chromedriver.chromium.org/downloads 여기서 다운로드하면 된다. 드라이버 설치가 귀찮다면 다음 코드를 통해 자동으로 호환되는 드라이버를 다운로드하고 관리할 수 있다.
#from selenium import webdriver
#from webdriver_manager.chrome import ChromeDriverManager
#driver = webdriver.Chrome(ChromeDriverManager().install())
하지만 난 이것에 실패했기 때문에...크롬 버전을 다운그레이드하던지, 119 버전을 지원하는 크롬드라이버의 베타 버전이나 개발자 버전을 찾아서 경로 설정을 해줘야한다. 버전을 다운그레이드하기에는 몇몇 부작용들이 있어서 119 버전을 찾았다..!
https://googlechromelabs.github.io/chrome-for-testing/
나는 stable에 있는 윈도우 64비트 url에서 다운로드받았다.
이제 다운로드받은 압축 폴더를 풀어서 나는 편리상 로컬 디스크(C:)에 저장해주었다.
options = Options()
options.add_argument('--headless') # 브라우저 창 숨기기
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
service = Service(executable_path='c:\chromedriver-win64\chromedriver.exe')
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
크롬 브라우저를 시작할 때 사용할 다양한 옵션을 설정한다. 브라우저 창 숨기기, GPU 가속 비활성화 등등 오류 방지를 위해 설정해주었다. 다음으로 드라이버를 저장해주었던 경로를 지정해서 Service 객체를 통해 WebDriver의 인스턴스를 생성할 때 필요한다. (이것은 Selenium4부터 도입되었다.) 이제 인스턴스를 생성하고 웹 페이지를 접속한다.
해당 상품의 유용한 순 리뷰와 평점 낮은 순 리뷰를 가져와보자.
# 유용한 순 리뷰 가져오기
data = driver.find_elements(By.CSS_SELECTOR, 'div.review-list')[:num]
if data:
up_reviews = reviewObject(data)
else:
up_reviews = None
# "낮은 평점 순"으로 리뷰 정렬
driver.find_element(By.CSS_SELECTOR, '#reviewSelectSort').click()
low_rating_option = driver.find_element(By.CSS_SELECTOR, 'option[value="goods_est_asc"]')
low_rating_option.click()
time.sleep(2) # 페이지 업데이트를 기다리기
# 낮은 평점 순 리뷰 가져오기
data = driver.find_elements(By.CSS_SELECTOR, 'div.review-list')[:num]
if data:
worst_reviews = reviewObject(data)
else:
worst_reviews = None
무신사 홈페이지에서는 리뷰 정렬 기능에 '유용한 순', '최신순', '댓글순', '높은 평점 순', '낮은 평점 순' 을 제공한다. 우리는 유용한 순과 낮은 평점 순을 가져와보겠다. 상품 페이지에서 리뷰들은 default로 유용한 순으로 정렬되어있다. 그래서 우선 유용한 순의 리뷰부터 저장해보겠다. 위에서 구현했던 reviewObject함수를 통해 리뷰 내용 중 필요한 값들만 '유용한 순' 리스트에 저장한다. 이후 낮은 평점 순으로 정렬 설정을 바꾸어 페이지를 업데이트한다. 그리고 똑같이 reviewObject함수를 통해 리뷰 내용 중 필요한 값들만 '낮은 평점 순' 리스트에 저장한다.
자 이제 유용한 순 리뷰 3개와 낮은 평점 순 리뷰 3개씩 가져와보자.
def GetReviews(url, num):
#현재까지 구현한 모든 코드
return up_reviews, worst_reviewsprint(GetReviews('https://www.musinsa.com/app/goods/836499', 3))

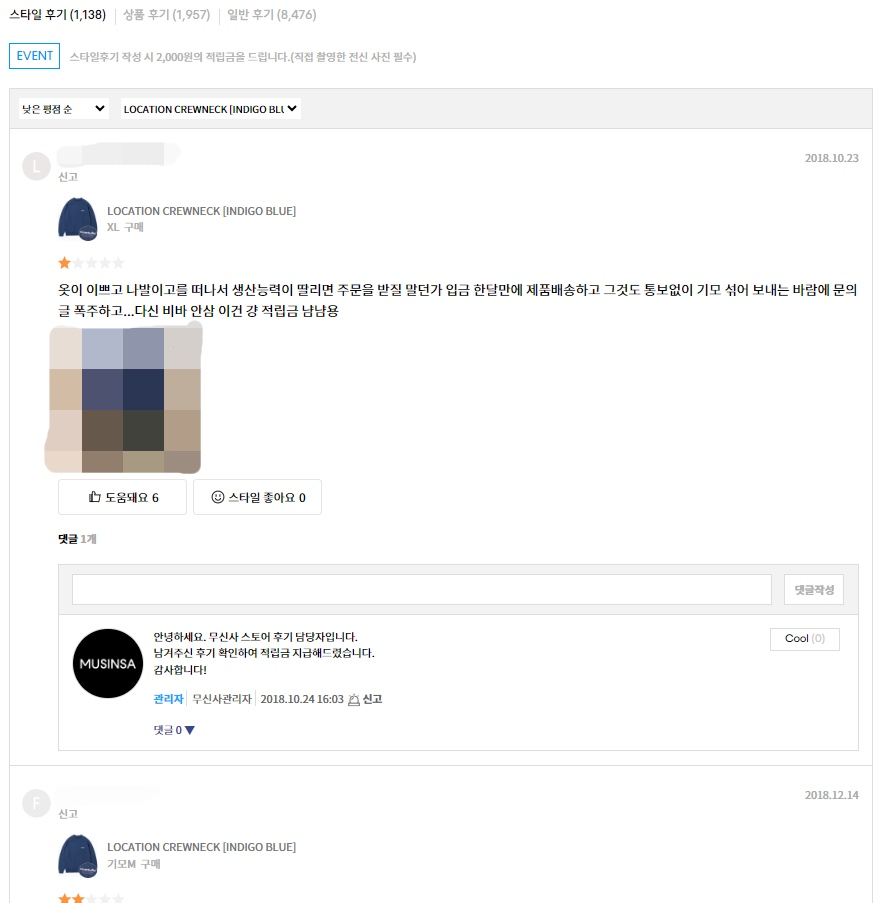
해당 상품의 실제 리뷰들과 비교해봤을때 똑같이 잘 나오는 것을 확인할 수 있다!
이제 다음에는 이 리뷰들을 활용해 상품에 대한 사용자와의 자유 질의응답을 구현해 볼 예정이다~!
'인공지능 > Generative AI' 카테고리의 다른 글
| [6탄] FastAPI 애플리케이션 Google Cloud Run(Docker)에 배포하기 (1) | 2023.11.26 |
|---|---|
| [5탄] Langchain+GPT+텍스트 임베딩으로 상품에 대한 질의응답하기 (0) | 2023.11.13 |
| [3탄] Beautifulsoup로 웹 크롤링하기 (0) | 2023.09.20 |
| [2탄]Langchain+GPT로 summary와 QA 해보기 (0) | 2023.09.10 |
| [1탄] ChatGPT Prompt Engineering & LangChain 을 활용한 온라인 가상 점원 프로젝트 (5) | 2023.05.26 |




댓글