CIFAR10에서 제공하는 컬러 이미지를 분류해 볼 것이다.
dataset에 대한 내용은 아래를 참고하자.
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu
데이터셋은 6K 이미지들로 구성된 클래스를 10개 갖는 60K 32*32 컬러 이미지들로 구성되어있습니다. 학습 이미지는 50K, 테스트 이미지는 10K이고, 각각 랜덤으로 섞인 클래스들로 구성된 배치를 5개, 1개 가진다.
클래스 10개의 이름은 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'.
우선 필요한 라이브러리를 import해준다.
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
데이터셋을 다운로드하고 준비한다.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
데이터세트가 올바른지 확인하기 위해 훈련 세트의 처음 25개 이미지를 플로팅하고 각 이미지 아래에 클래스 이름을 표시해보자.
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
#Create 10X10 inches figure
plt.figure(figsize=(10,10))
for i in range(25):
#5X5 grid to plot individual images
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()
합성곱 층과 풀링 층을 만들어보자. 이를 통해 여러 레이어를 통과시키면서 점차적으로 더 낮은 차원의 특징 맵으로 변환되어, 이 과정에서 이미지의 중요한 특징들을 추출하게 된다.
model = models.Sequential()
#레이어에서 생성될 필터(커널)의 수 :32 , 각 필터의 크기 : 3X3, 데이터셋 이미지 : 32X32 픽셀 크기, 33개의 채널(RGB)
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
#최대 풀링 레이어를 추가하여 이미지의 높이와 너비를 반으로 줄임
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
지금까지 모델의 아키텍쳐를 표시해보자.
결과를 살펴보니, 첫 번째 합성곱 레이어를 통과한 후 3x3 커널을 사용했기에 높이와 너비가 각각 2픽셀씩 줄어들어 30X30이 되었다. 또한 32개의 필터를 사용했기 때문에 출력 깊이는 32이다. 최대 풀링 레이어를 통과하면 높이와 너비가 반으로 줄어드는 것을 확인할 수 있다.
model.summary()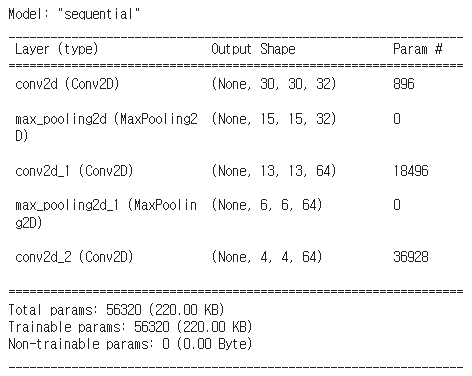
이제 Flatten 레이어를 통해 입력을 일차원 배열로 평탄화한 후, 완전 연결 레이어를 추가해준다.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
모델의 전체 아키텍쳐를 확인해보자.
flatten 레이어를 통해 1024(4*4*64) 평탕화가 진행된 것을 알 수 있다. dense는 64개의 뉴런을 가진 완전 연결 레이어이며, dense_1은 10개의 뉴런을 가진 완전 연결 레이어로, 각 클래스에 대한 점수를 출력한다.
model.summary()
모델 컴파일과 훈련을 진행해보자.
우선 최적화 알고리즘 'adam'을 사용하고 손실 함수로는 Sparse Categorical Crossentropy를 사용한다. metrics=['accuracy']를 통해 학습 도중에 정확도를 모니터링하고 기록하도록 한다.
전체 학습 데이터셋을 10번 반복하여 모델을 학습시키고, 각 epoch후에 모델의 성능을 평가하기 위해 검증 데이터셋을 통해 학습 데이터가 과적합되지 않았는지 확인할 수 있다.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
이제 모델의 학습 과정에서의 정확도를 시각화하고, 테스트 데이터셋에 대한 모델의 성능을 평가해보자.
우선 첫번째 줄은 학습 데이터셋에 대한 정확도를 그래프로 그리는 것이고, val_accuracy는 검증 데이터셋에 대한 정확도를 그래프로 그린 것이다. x축의 레이블은 Epoch로 설정하고, y축은 Accuracy로 설정한다. y축의 범위를 0.5에서 1사이로 설정하고, 그래프의 범례를 오른쪽 하단에 위치시킨다.
마지막 줄을 통해 테스트 데이터셋에 대한 모델의 손실과 정확도를 반환한다.
#시각화
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
#모델 평가
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
마지막 val_accuracy 값을 출력해보자.
print(test_acc)
70% 이상의 테스트 정확도를 달성했다.
'인공지능 > Deep Learning' 카테고리의 다른 글
| [DL] LSTM으로 전력 사용량 예측하기 (데이콘) - 단일 변수 (0) | 2023.11.26 |
|---|---|
| [DL] LSTM(Long Short-Term Memory) (1) | 2023.11.12 |
| [DL] RNN으로 IMDB 리뷰 분류하기+단어 임베딩 (0) | 2023.11.05 |
| [DL] RNN(Recurrent Neural Network : 순환 신경망) (0) | 2023.11.03 |
| [DL] CNN(Convolutional Neural Network : 합성곱 신경망) (0) | 2023.09.18 |




댓글