https://dacon.io/competitions/official/236125/data
2023 전력사용량 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
데이콘에서 진행한 전력 사용량 예측하기 모델에 대한 EDA를 해보겠다.
우선 데이터셋을 다운로드받아 확인해보자.
1. train.csv : 100개 건물들의 2022년 06월 01일부터 2022년 08월 24일까지의 데이터(전력사용량, 일시, 기온 등)
2. test.csv : 100개 건물들의 2022년 08월 25일부터 2022년 8월 31일까지의 데이터 (전력사용량, 일시, 기온 등)
3. building_info.csv : 100개 건물 정보 (건물 번호, 유형, 연면적 등)
데이터셋 확인
train_df.head()
test_df.head()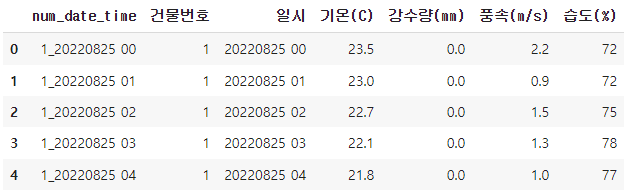
한글 라벨을 모두 영어로 변환해주고 num_date_time은 건물번호+일시라서 drop해준다.
train_df = train_df.rename(columns={
'건물번호': 'building_number',
'일시': 'date_time',
'기온(C)': 'temperature',
'강수량(mm)': 'rainfall',
'풍속(m/s)': 'windspeed',
'습도(%)': 'humidity',
'일조(hr)': 'sunshine',
'일사(MJ/m2)': 'solar_radiation',
'전력소비량(kWh)': 'power_consumption'
})
train_df.drop('num_date_time', axis = 1, inplace=True)test_df = test_df.rename(columns={
'건물번호': 'building_number',
'일시': 'date_time',
'기온(C)': 'temperature',
'강수량(mm)': 'rainfall',
'풍속(m/s)': 'windspeed',
'습도(%)': 'humidity',
'일조(hr)': 'sunshine',
'일사(MJ/m2)': 'solar_radiation',
'전력소비량(kWh)': 'power_consumption'
})
test_df.drop('num_date_time', axis = 1, inplace=True)building_info도 영어로 변환해준다.
building_info = building_info.rename(columns={
'건물번호': 'building_number',
'건물유형': 'building_type',
'연면적(m2)': 'total_area',
'냉방면적(m2)': 'cooling_area',
'태양광용량(kW)': 'solar_power_capacity',
'ESS저장용량(kWh)': 'ess_capacity',
'PCS용량(kW)': 'pcs_capacity'
})translation_dict = {
'건물기타': 'Other Buildings',
'공공': 'Public',
'대학교': 'University',
'데이터센터': 'Data Center',
'백화점및아울렛': 'Department Store and Outlet',
'병원': 'Hospital',
'상용': 'Commercial',
'아파트': 'Apartment',
'연구소': 'Research Institute',
'지식산업센터': 'Knowledge Industry Center',
'할인마트': 'Discount Mart',
'호텔및리조트': 'Hotel and Resort'
}
building_info['building_type'] = building_info['building_type'].replace(translation_dict)
결측치 확인
데이터 분석을 위해 두 csv 파일을 합쳐준다. (train+test)
train_df = pd.merge(train_df, building_info, on='building_number', how='left')
test_df = pd.merge(test_df, building_info, on='building_number', how='left')train_df.isna().sum()
test_df.isna().sum()
train_df에는 많은 양의 결측치를 보여주는 반면, test_df는 결측치가 보이지 않는다. 또한 solar_power_capcity, ess, pcs에는 -로 결측치가 되어있다. 이를 drop해준다.
train_df = train_df.drop(['solar_power_capacity', 'ess_capacity', 'pcs_capacity'], axis=1)
test_df = test_df.drop(['solar_power_capacity', 'ess_capacity', 'pcs_capacity'], axis=1)
datetime을 년도, 월, 주, 시간으로 쪼개준다.
train_df['date_time'] = pd.to_datetime(train_df['date_time'], format='%Y%m%d %H')
# date time feature 생성
train_df['hour'] = train_df['date_time'].dt.hour
train_df['day'] = train_df['date_time'].dt.day
train_df['month'] = train_df['date_time'].dt.month
train_df['year'] = train_df['date_time'].dt.year
데이터 시각화
power consumtion 분포
# histogram 생성
plt.figure(figsize=(10, 6))
sns.histplot(train_df['power_consumption'], bins=30, kde=True)
plt.title('Distribution of Power Consumption')
plt.xlabel('Power Consumption')
plt.ylabel('Frequency')
plt.show()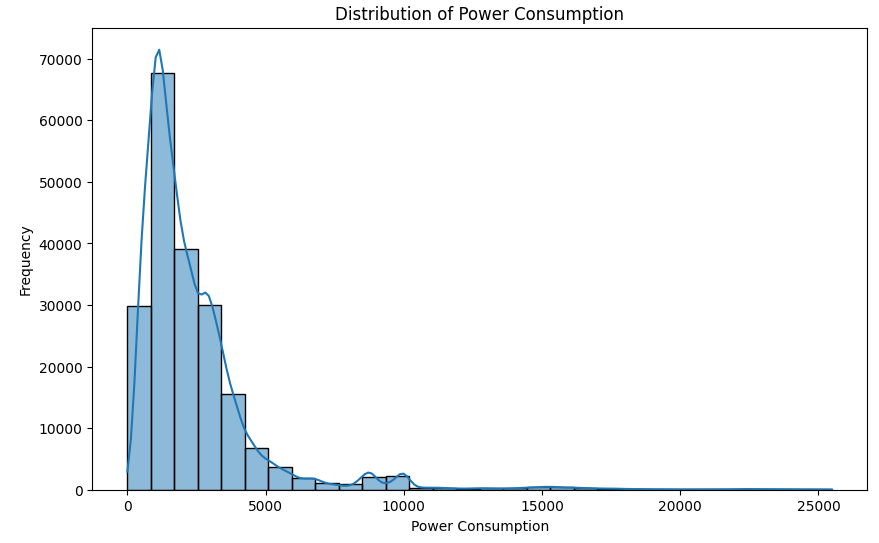
소비 전력 평균 분포 시각화
# 년기준 일 평균 소비전력
train_df['day_of_year'] = train_df['date_time'].dt.dayofyear
mean_power_by_day_of_year = train_df.groupby('day_of_year')['power_consumption'].mean()
# 년기준 시간평균 소비전력
train_df['hour_of_year'] = train_df['date_time'].dt.hour + (train_df['date_time'].dt.dayofyear - 1) * 24
mean_power_by_hour_of_year = train_df.groupby('hour_of_year')['power_consumption'].mean()
# 년기준 월평균 소비전력
mean_power_by_month = train_df.groupby('month')['power_consumption'].mean()
# 일기준 시간 평균 소비전력
mean_power_by_hour = train_df.groupby('hour')['power_consumption'].mean()
# 월기준 시간 평균 소비전력
mean_power_by_day = train_df.groupby('day')['power_consumption'].mean()plt.figure(figsize=(10, 6))
sns.lineplot(x=mean_power_by_day_of_year.index, y=mean_power_by_day_of_year.values)
plt.title('Mean Power Consumption by Day of the Year')
plt.xlabel('Day of the Year')
plt.ylabel('Mean Power Consumption')
plt.show()
중간중간 훅하고 떨어지는 모습은 주말에 일을 하지 않으니 떨어지는 모습을 보이는 것 같네요.
plt.figure(figsize=(10, 6))
sns.lineplot(x=mean_power_by_hour_of_year.index, y=mean_power_by_hour_of_year.values)
plt.title('Mean Power Consumption by Hour of the Year')
plt.xlabel('Hour of the Year')
plt.ylabel('Mean Power Consumption')
plt.show()
fig, axs = plt.subplots(3, 1, figsize=(10, 18))
# Plot mean power consumption by hour of the day
sns.lineplot(x=mean_power_by_hour.index, y=mean_power_by_hour.values, ax=axs[0])
axs[0].set_title('Mean Power Consumption by Hour of the Day')
axs[0].set_xlabel('Hour of the Day')
axs[0].set_ylabel('Mean Power Consumption')
# Plot mean power consumption by day of the month
sns.lineplot(x=mean_power_by_day.index, y=mean_power_by_day.values, ax=axs[1])
axs[1].set_title('Mean Power Consumption by Day of the Month')
axs[1].set_xlabel('Day of the Month')
axs[1].set_ylabel('Mean Power Consumption')
# 년기준 월평균 소비전력
sns.lineplot(x=mean_power_by_month.index, y=mean_power_by_month.values, ax=axs[2])
axs[2].set_title('Mean Power Consumption by Month of the Year')
axs[2].set_xlabel('Month of the Year')
axs[2].set_ylabel('Mean Power Consumption')
plt.tight_layout()
plt.show()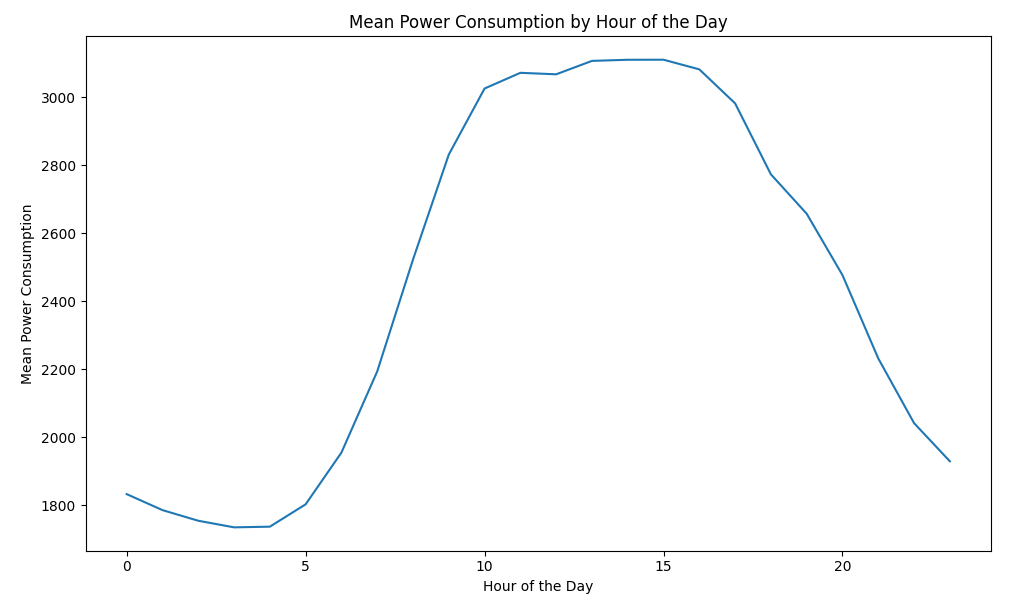
낮 시간대에 전력 소모량이 증가하는 걸 보니, 사람들이 일하는 시간에 증가하는 것으로 보이네요.
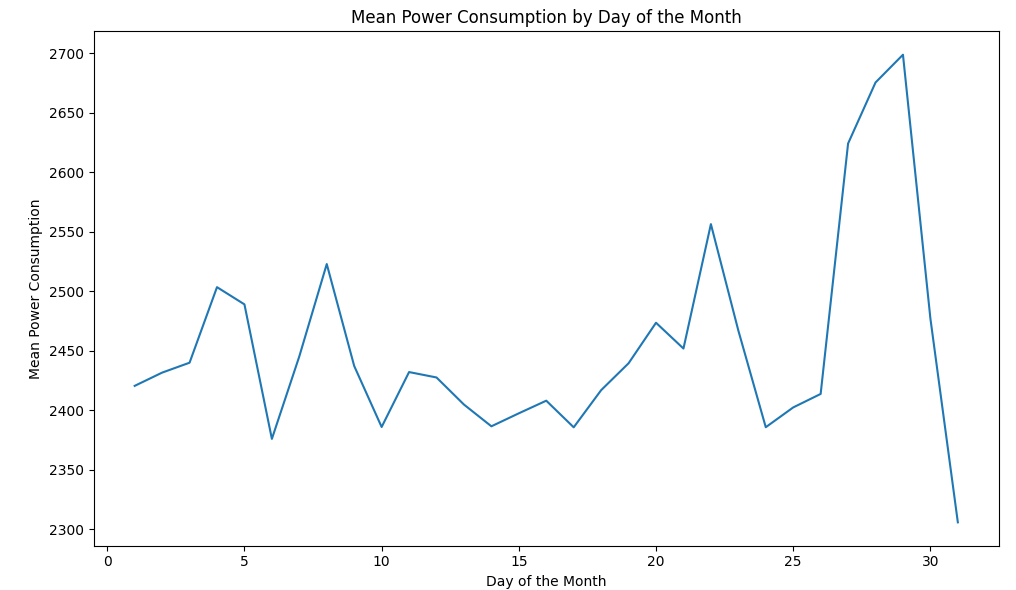

8월에 가까워질수록 전력 사용량이 증가하는 모습을 보이네요. (더워질수록 에어컨을 더 많이 키니까요.)
train_df['day_of_week'] = train_df['date_time'].dt.dayofweek
# 요일별 전력평균
mean_power_by_day_of_week = train_df.groupby('day_of_week')['power_consumption'].mean()
plt.figure(figsize=(10, 6))
sns.barplot(x=mean_power_by_day_of_week.index, y=mean_power_by_day_of_week.values)
plt.title('Mean Power Consumption by Day of the Week')
plt.xlabel('Day of the Week (0=Monday, 6=Sunday)')
plt.ylabel('Mean Power Consumption')
plt.show()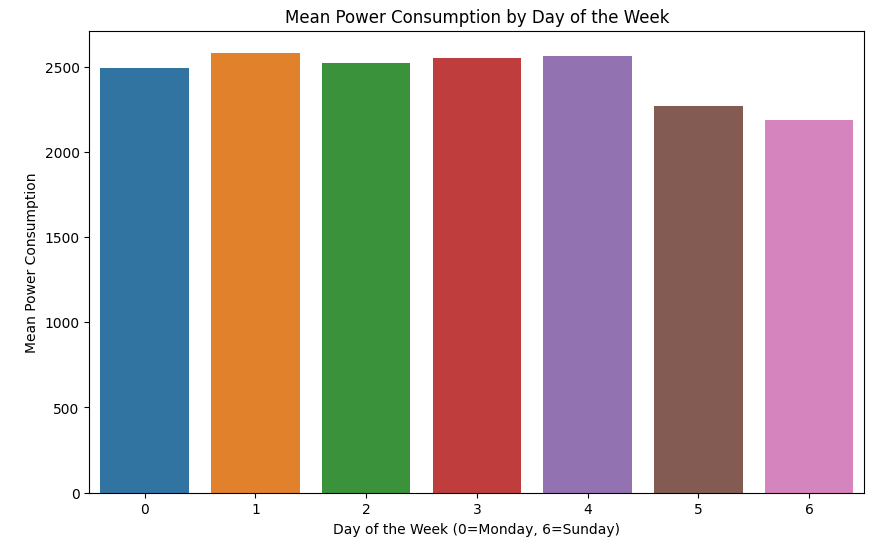
확실히 주말보다 평일에 더 많네요.
building type별 데이터 소비 전력 평균 분포 시각화
plt.figure(figsize=(12, 8))
sns.boxplot(x='building_type', y='power_consumption', data=train_df)
plt.title('Power Consumption by Building Type')
plt.xticks(rotation=90)
plt.show()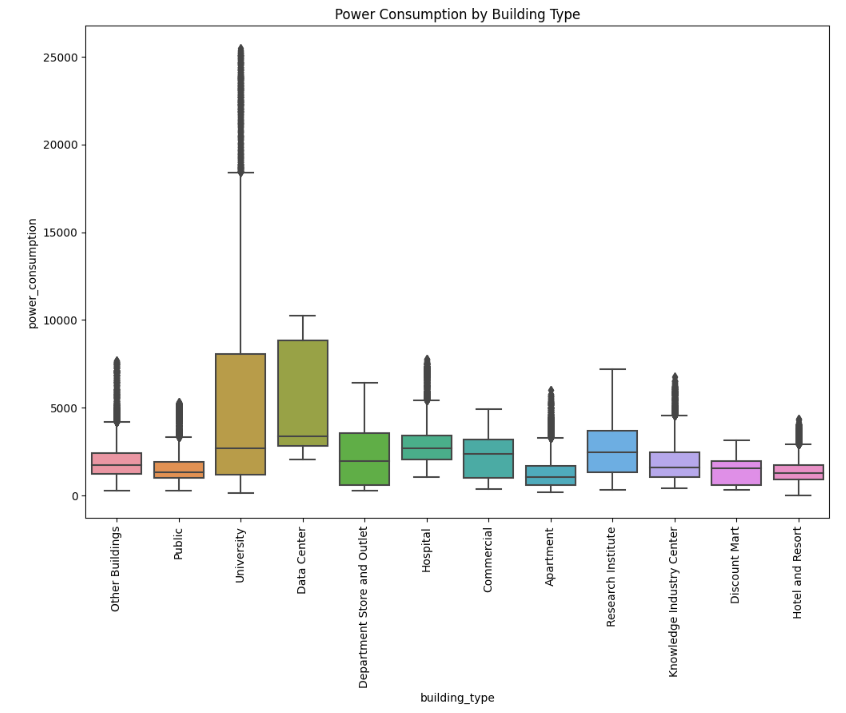
mean_power_by_hour_building = train_df.groupby(['hour', 'building_type'])['power_consumption'].mean().reset_index()
pivot_df = mean_power_by_hour_building.pivot(index='hour', columns='building_type', values='power_consumption')
plt.figure(figsize=(15, 10))
sns.lineplot(data=pivot_df)
plt.title('Mean Power Consumption by Hour of Day and Building Type')
plt.xlabel('Hour of Day')
plt.ylabel('Mean Power Consumption')
plt.legend(title='Building Type')
plt.show()
data center와 university에서 아주 많은 양의 전력을 소모하네요.대부분 낮시간에 전력을 많이 소모하지만 data center와 apartment는 다른 양상을 띄네요. data center의 경우, 일정한 모습을 보여주네요.
mean_power_by_day_building = train_df.groupby(['day_of_week', 'building_type'])['power_consumption'].mean().reset_index()
pivot_df_day = mean_power_by_day_building.pivot(index='day_of_week', columns='building_type', values='power_consumption')
day_names = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
pivot_df_day.index = day_names
plt.figure(figsize=(15, 10))
sns.lineplot(data=pivot_df_day)
plt.title('Mean Power Consumption by Day of Week and Building Type')
plt.xlabel('Day of Week')
plt.ylabel('Mean Power Consumption')
plt.legend(title='Building Type')
plt.show()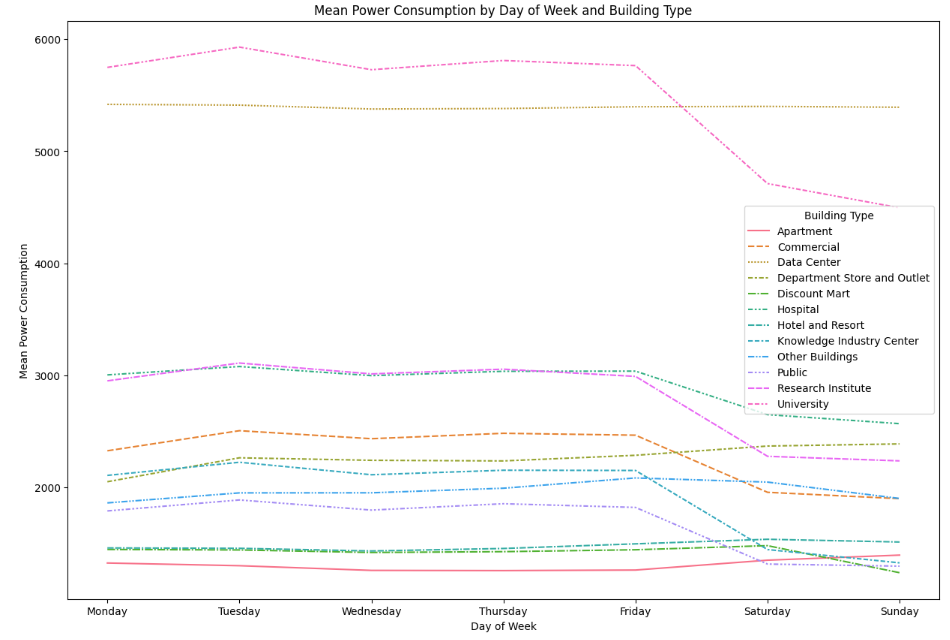
주말에 전력 소비가 대체로 낮아지지만 아파트나 상가는 오히려 증가하네요. data center의 경우, 역시 일정한 모습을 보이네요.
데이콘 코드공유 '느아'님의 코드를 참고했습니다.
'Data > 데이터분석' 카테고리의 다른 글
| 시계열 데이터 정상성(Stationarity)과 차분 (0) | 2023.09.11 |
|---|---|
| 시계열 데이터의 정의와 구성요소, 시계열 분해 (0) | 2023.09.04 |


댓글