시계열 데이터란?
시계열 데이터란 일정한 시간동안 수집된 일련의 순차적으로 정해진 데이터 셋의 집합이다. 시계열 데이터의 분석 목적은 시계열이 갖고 있는 법칙성을 발견해 이를 모형화하고, 또 추정된 모형을 통하여 미래의 값을 예측하는 것이다. 예를 들어, 일일 주가, 분 단위 센서 데이터, 월간 판매량 등이 시계열 데이터의 예시이다.
시계열 데이터의 종류
- 등간격 규칙을 갖는 시계열 데이터
- 불규칙 간격을 갖는 시계열 데이터
- 등간격 규칙을 갖으나 결측값이 포함된 시계열 데이터
시계열 데이터의 구성요소
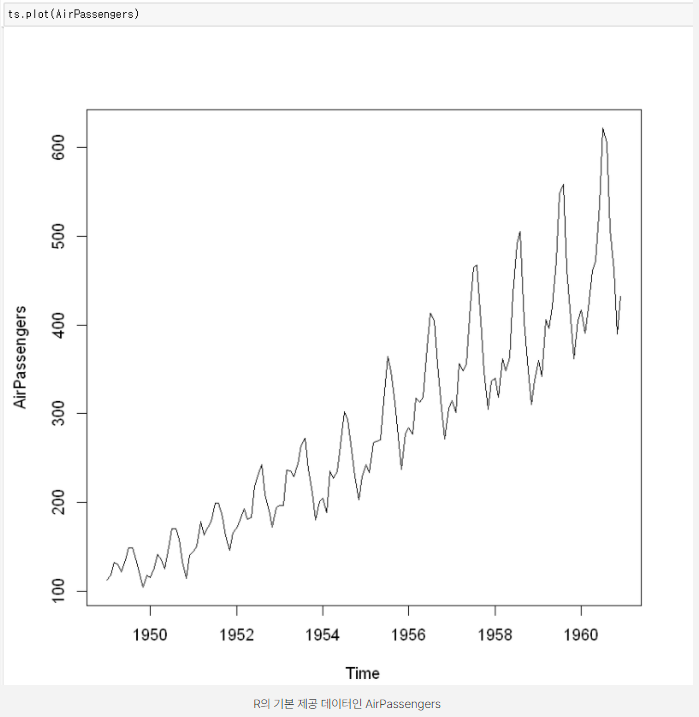
- 추세 : 장기적으로 증가하거나, 감소하는 경향성이 존재하는 것 (위 그래프는 상승하는 추세)
- 계절성 : 계절적 요인의 영향을 받아 1년 혹은 일정 기간 안에 반복적으로 나타나는 패턴 (위 그래프는 월별 데이터가 뚜렷한 주기를 지닌 상태로 등락을 거듭하고 있음)
- 주기성 : 순환 성분이라고도 불리며 정해지지 않은 빈도, 기간으로 일어나는 상승 혹은 하락, 보통 주기성은 경제 상황 때문에 일어나 경기 순환과 관련되어 있음
시계열 분해

시계열 분해는 시계열을 여러개의 구성요소로 분해하는 통계적인 방법을 말한다. 시계열 분해에서 시계열 데이터는 체계적 성분과 불규칙적 성분으로 이루어졌다고 가정하며, 이를 분리하여 시계열 데이터를 분석하고 예측하는 것이 시계열 분해의 목적이다.
위 그래프에서 방금 전 확인했던 데이터의 구성요소를 쉽게 파악할 수 있다. 마지막에 있는 random은 앞의 시계열 분해 후 남는 나머지(residuals)를 의미한다. 시계열 분석에서 이 나머지 부분이 중요한데, 이 부분에 더이상 가진 정보가 없게 (백색잡음이 되도록) 하는 것이 시계열 분석에서 매우 큰 부분을 차지하고 있기 때문이다.
다음으로 시계열의 정상성과 분석 예제들을 살펴볼 예정이다.
'Data > 데이터분석' 카테고리의 다른 글
| [EDA] 전력 사용량 시계열 데이터 분석하기 (데이콘) (1) | 2023.11.26 |
|---|---|
| 시계열 데이터 정상성(Stationarity)과 차분 (0) | 2023.09.11 |


댓글