- Tree-based learning algorithms, also known as Cart (Classification and Regression Trees), are a popular technique for predicting numeric and categorical outputs.
- Tree-based methods, which include decision trees, bagging, random forests, and boosting, are considered highly effective in the space of supervised learning.
- This is partly due to their high accuracy and versatility as they can be used to predict both discrete and continuous outcomes.
Decision Trees
- Decision trees create a decision structure to interpret patterns by splitting data into groups using variables that best split the data into homogenous or numerically relevant groups based on entropy (a measure of variance in the data among different classes).
- The primary appeal of decision trees is they can be displayed graphically as a tree-like graph.
- Unlike an actual tree, the decision tree is displayed upside down with the leaves located at the bottom or foot of the free.
- Each branch represents the outcome of a decision/variable and each leaf node represents a class label, such as “Go to beach” or “Stay in.”
- Decision rules are subsequently marked by the path from the root of the tree to a terminal leaf node.

Example
Let’s use a decision tree classifier to predict the outcome of a user clicking on an advert using the advertising dataset.
1-2. Import libraries/ Dataset
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
df = pd.read_csv('/content/advertising.csv')3. Convert non-numeric variables
df = pd.get_dummies(df, columns=['Country', 'City'])4. Remove columns
del df['Ad Topic Line']
del df['Timestamp']
df.head()
5. Set X and y variables
X = df.drop('Clicked on Ad',axis=1)
y = df['Clicked on Ad']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10, shuffle=True)6. Set algorithm
model = DecisionTreeClassifier()
model.fit(X_train,y_train)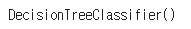
7. Evaluate
model_predict = model.predict(X_test)
print(confusion_matrix(y_test, model_predict))
print(classification_report(y_test, model_predict))
https://github.com/erica00j/machinelearning/blob/main/decision_Tree.ipynb
GitHub - erica00j/machinelearning
Contribute to erica00j/machinelearning development by creating an account on GitHub.
github.com
'인공지능 > Machine Learning' 카테고리의 다른 글
| [ML] Tree Based Learning Algorithms - Gradient Boosting (0) | 2022.11.30 |
|---|---|
| [ML] Tree Based Learning Algorithms - Random Forests (0) | 2022.11.30 |
| [ML] k-NEAREST NEIGHBORS 예제 (0) | 2022.11.15 |
| [ML] k-NEAREST NEIGHBORS (k-최근접 이웃 알고리즘) (0) | 2022.11.15 |
| [ML] Bias & Variance (0) | 2022.11.15 |




댓글