[ML] Tree Based Learning Algorithms - Random Forests
by 유일리2022. 11. 30.
Decision trees technique is prone to overfitting.
Decision trees are accurate at decoding patterns using the training data.
But because there is a fixed sequence of decision paths, any variance in the test data or new data can result in poor predictions.
The fact that there is only one tree design also limits the flexibility of this methodto manage variance and future outliers.
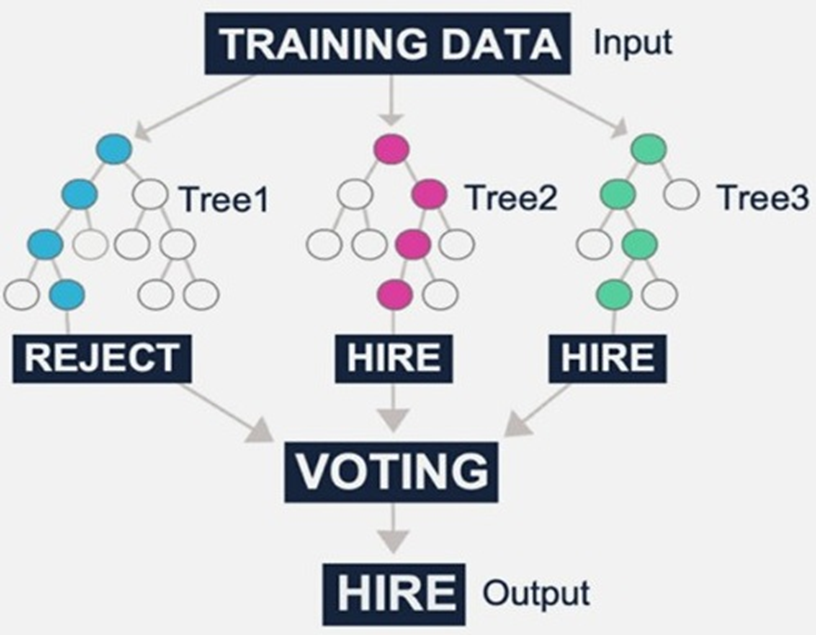
A solution for mitigating overfitting is to grow multiple trees using a different technique called random forests.
This method involves growing multiple decision trees using a randomized selection of input data for each tree and combining the results by averaging the output for regression or class voting for classification.
If the entire forest inspected a full set of variables, each tree would look similar,as the trees would each attempt to maximize information gain at the subsequent layer and thereby select the optimal variable at each split.
Unlike a standard decision tree, though, which has a full set of variables to draw from, the random forests algorithm has an artificially limited set of variables available to build decisions.
Due to fewer variables shown and the randomized data provided, random forests are less likely to generate a collection of similar trees.
Embracing randomness and volume, random forests are subsequently capable ofproviding a reliable result with potentially less variance and overfitting than a single decision tree.
Example
1-2. Import libraries / dataset
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
df = pd.read_csv('/content/advertising.csv')
X = df.drop('Clicked on Ad',axis=1)
y = df['Clicked on Ad']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10, shuffle=True)
6.Set algorithm
model = RandomForestClassifier(n_estimators=150)
model.fit(X_train, y_train)
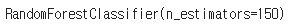





댓글